
More Efficient NLP Model Pre-training with ELECTRA
Recent advancements in language pre-training have significantly improved natural language processing (NLP). Models like BERT, RoBERTa, XLNet, ALBERT, and T5 demonstrate state-of-the-art performance. These models leverage vast amounts of unlabeled text to create a general language understanding model, later fine-tuned for specific NLP tasks (e.g., sentiment analysis, question answering).
Existing pre-training methods are broadly categorized into:
- Language Models (LMs): Process text left-to-right, predicting the next word (e.g., GPT).
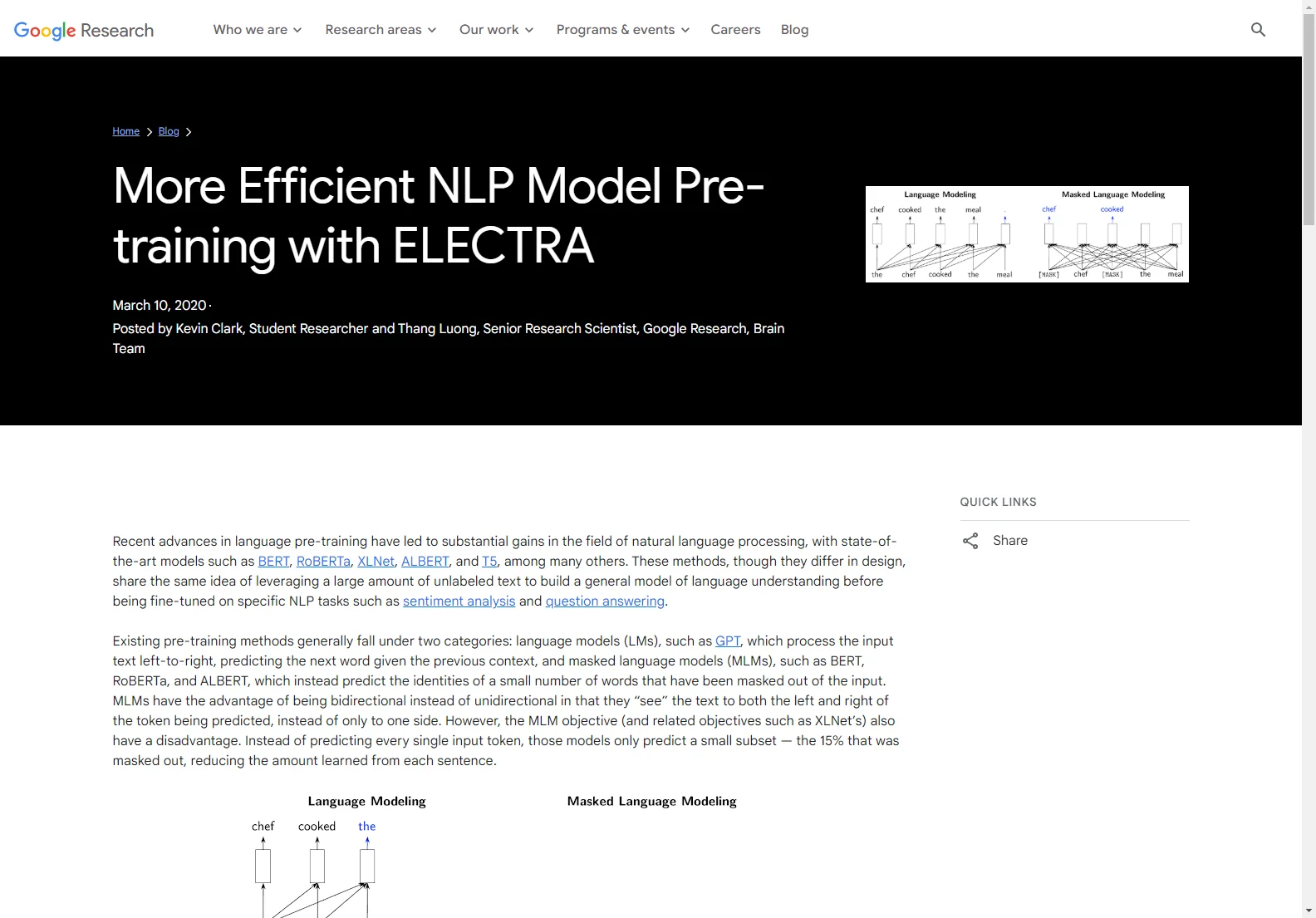
- Masked Language Models (MLMs): Predict masked words within the input, allowing for bidirectional context (e.g., BERT, RoBERTa, ALBERT).
MLMs offer the advantage of bidirectionality but suffer from inefficiency; they only predict a small subset (e.g., 15%) of masked words, limiting learning from each sentence.
ELECTRA: A More Efficient Approach
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) offers a novel pre-training method that surpasses existing techniques in efficiency. It achieves comparable performance to RoBERTa and XLNet using significantly less compute (less than ¼). ELECTRA also sets a new state-of-the-art on the SQuAD question answering benchmark.
ELECTRA's efficiency extends to smaller scales; it can be trained on a single GPU in a few days, outperforming GPT which requires over 30 times more compute.
How ELECTRA Works
ELECTRA employs a new pre-training task called replaced token detection (RTD). Inspired by Generative Adversarial Networks (GANs), it trains a bidirectional model while learning from all input positions. Instead of masking words with “[MASK]”, ELECTRA replaces some tokens with plausible but incorrect alternatives. The model then distinguishes between real and fake tokens.
This binary classification task is applied to every token, unlike MLMs which only focus on a subset. This makes RTD significantly more efficient, requiring fewer examples to achieve comparable performance.
The replacement tokens are generated by a smaller masked language model (the generator) that is trained jointly with the discriminator (ELECTRA). While structurally similar to a GAN, the generator is trained with maximum likelihood, avoiding the complexities of adversarial training in text.
ELECTRA Results
ELECTRA demonstrates significant improvements over existing models, achieving comparable GLUE scores to RoBERTa and XLNet with substantially less compute. Even a small ELECTRA model trained on a single GPU outperforms GPT with a fraction of the compute.
A large-scale ELECTRA model achieves state-of-the-art results on the SQuAD 2.0 question answering dataset, surpassing RoBERTa, XLNet, and ALBERT.
Conclusion
ELECTRA presents a highly efficient pre-training method for NLP models. Its innovative approach to replaced token detection leads to significant improvements in performance while reducing computational requirements. The open-source release of ELECTRA, including pre-trained weights, makes it accessible for a wide range of NLP tasks.