
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
Ever since BERT's introduction, natural language research has adopted a new paradigm: using vast amounts of text to pretrain model parameters via self-supervision, eliminating the need for data annotation. Instead of training NLP models from scratch, researchers can begin with a model already possessing language knowledge. However, to improve this approach, understanding the factors influencing language understanding performance is crucial – network depth, width, self-supervision learning criteria, or other elements?
The paper "ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations" (accepted at ICLR 2020) introduces an enhanced BERT model that surpasses state-of-the-art performance on 12 NLP tasks, including SQuAD v2.0 and the RACE benchmark. ALBERT is open-source on TensorFlow and includes pre-trained language representation models.
What Contributes to NLP Performance?
Determining the primary driver of NLP performance is complex. ALBERT's design focuses on efficient capacity allocation. Input-level embeddings (words, sub-tokens) learn context-independent representations, while hidden-layer embeddings refine these into context-dependent representations.
This is achieved through factorization of the embedding parametrization – splitting the embedding matrix into low-dimensional input-level embeddings (e.g., 128) and higher-dimensional hidden-layer embeddings (e.g., 768). This reduces parameters by 80% with minimal performance loss.
Another key design choice addresses redundancy in transformer-based architectures. ALBERT employs parameter-sharing across layers, reducing parameters by 90% in the attention-feedforward block (70% overall). While accuracy slightly decreases, the smaller size is advantageous.
Combining these changes creates an ALBERT-base model with 12M parameters (89% reduction compared to BERT-base), maintaining respectable performance. This reduction allows scaling up hidden-layer embeddings, leading to the ALBERT-xxlarge configuration (4096 hidden size). This achieves a 30% parameter reduction compared to BERT-large and significant performance gains on SQuAD2.0 (+4.2) and RACE (+8.5).
Optimized Model Performance with the RACE Dataset
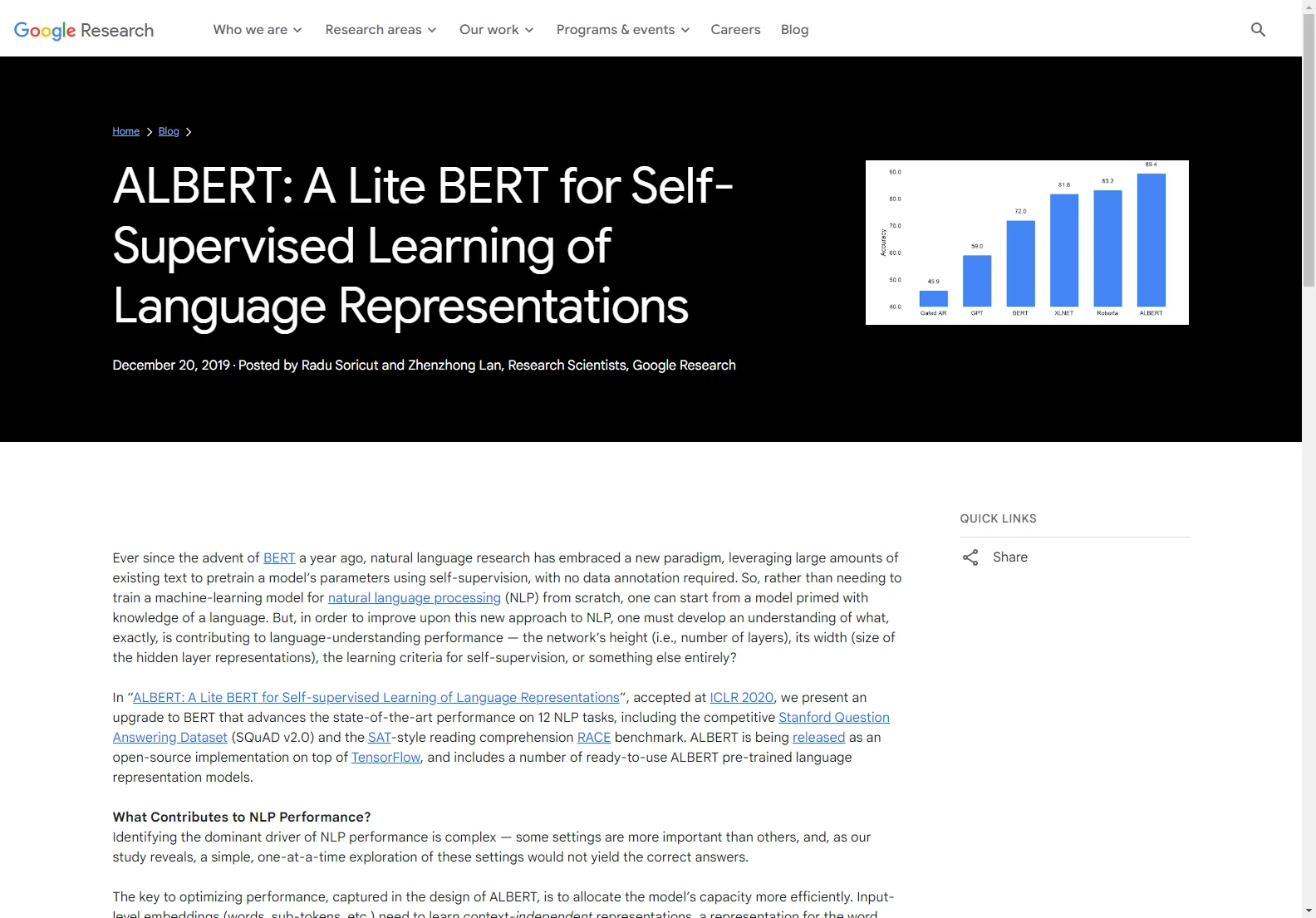
The RACE dataset (2017) is used to evaluate language understanding. ALBERT-xxlarge, trained on the base BERT dataset, achieves a RACE score comparable to other refined models. However, when trained on a larger dataset (like XLNet and RoBERTa), it sets a new state-of-the-art score of 89.4.
Conclusion
ALBERT's success highlights the importance of identifying model aspects that contribute to powerful contextual representations. By focusing on these aspects, both efficiency and performance across various NLP tasks are significantly improved. ALBERT's open-source nature facilitates further advancements in NLP.