Phenaki: A Revolutionary AI Model for Video Generation
Phenaki is a groundbreaking AI model capable of generating realistic videos from a sequence of textual prompts. Unlike previous models, Phenaki can create videos of arbitrary length, incorporating prompts that change over time – essentially, telling a story through text and translating it into a video.
Key Features and Capabilities
- Long-Form Video Generation: Phenaki can generate videos lasting several minutes, a significant advancement in AI video synthesis.
- Time-Variable Prompts: The model accepts a sequence of prompts, allowing for dynamic changes in the video's narrative and visual elements.
- Realistic Video Synthesis: Phenaki produces videos with high spatio-temporal quality, surpassing previous per-frame baselines.
- Efficient Video Representation: The model uses a causal model for learning video representation, compressing videos into a compact set of discrete tokens.
- Open Domain Generation: Phenaki can generate videos across a wide range of topics and styles.
How Phenaki Works
Phenaki employs an encoder-decoder architecture. The encoder compresses the video into a sequence of tokens, while the decoder generates new video tokens based on the input text prompts. A bidirectional masked transformer conditions the generated video tokens on pre-computed text tokens, enabling coherent video generation from textual input.
The model's training leverages a large corpus of image-text pairs and a smaller set of video-text examples. This joint training approach enables Phenaki to generalize effectively, even beyond the limitations of available video datasets.
Examples of Phenaki's Capabilities
Phenaki's versatility is showcased through various examples:
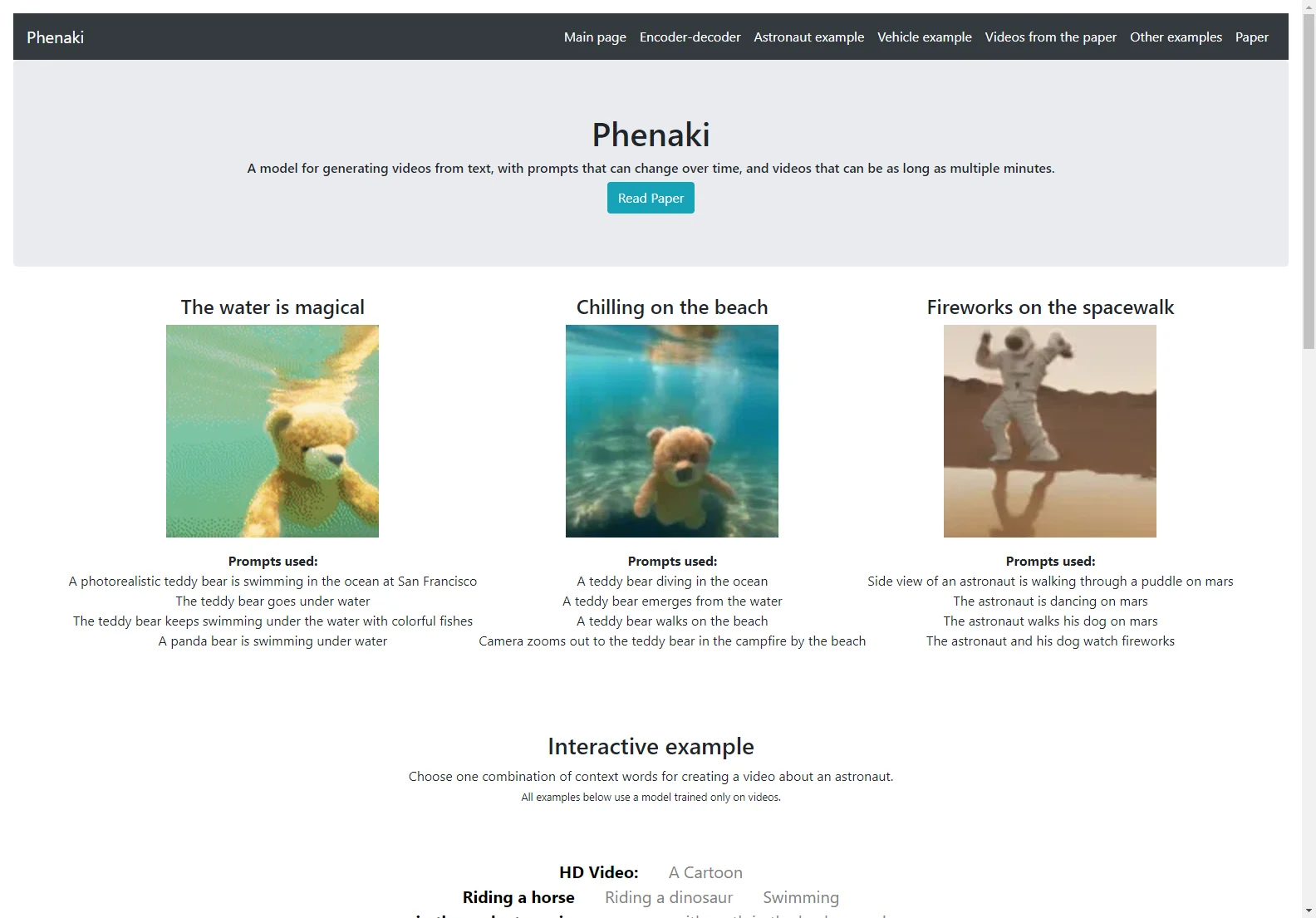
- Astronaut on Mars: The model can generate videos depicting an astronaut performing different actions on Mars, seamlessly transitioning between scenes based on changing prompts.
- Teddy Bear Adventures: A teddy bear can be seen swimming underwater, then walking on a beach, all generated from a series of descriptive prompts.
- Futuristic Cityscape: Phenaki can create a complex, multi-scene video of a futuristic city, including an alien spaceship and a lion in a suit, all driven by a detailed sequence of textual instructions.
Comparisons to Other Models
Phenaki significantly outperforms existing video generation models in several key areas: video length, handling of time-variable prompts, and overall video quality. Its ability to generate long, coherent videos from complex textual instructions sets it apart from previous approaches.
Conclusion
Phenaki represents a major leap forward in AI video generation. Its ability to create realistic, long-form videos from dynamic textual prompts opens up exciting possibilities for storytelling, animation, and various other creative applications.