
Introducing CM3leon: A More Efficient Generative Model for Text and Images
CM3leon (pronounced like "chameleon") is a groundbreaking foundation model capable of both text-to-image and image-to-text generation. Developed by Meta AI, it achieves state-of-the-art performance in text-to-image generation while requiring significantly less computational power than previous transformer-based methods. This efficiency is achieved through a novel training recipe adapted from text-only language models, incorporating large-scale retrieval-augmented pre-training and multitask supervised fine-tuning.
Key Features and Capabilities
CM3leon's unique architecture allows it to generate sequences of text and images based on various input combinations. This multimodal capability surpasses previous models limited to either text-to-image or image-to-text generation. Key features include:
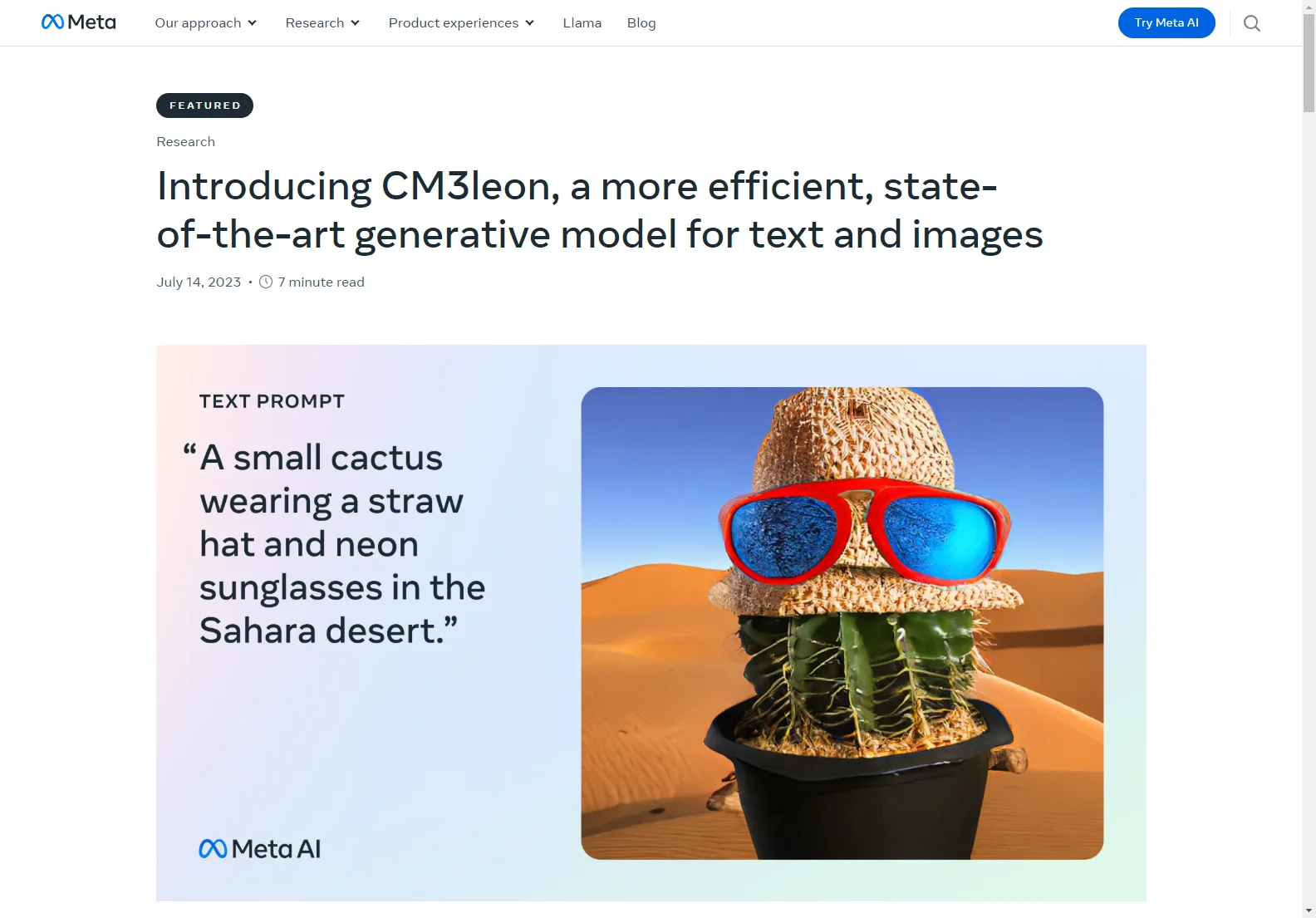
- Text-guided image generation and editing: Creates coherent images from complex prompts and edits existing images based on text instructions.
- High-quality image generation: Produces detailed and visually appealing images, overcoming challenges faced by other models in rendering global shapes and local details.
- Multitask capabilities: Excels in various tasks such as image caption generation, visual question answering, text-based editing, and conditional image generation, all using a single model.
- Efficiency: Trained with significantly less compute than comparable models, making it more resource-friendly.
- Strong performance: Achieves a new state-of-the-art FID score of 4.88 on the zero-shot MS-COCO benchmark, outperforming Google's Parti model.
How CM3leon Works
CM3leon's architecture utilizes a decoder-only transformer, similar to successful text-based models. Its ability to process and generate both text and images is what sets it apart. The training process involves retrieval augmentation, improving efficiency and control, followed by instruction fine-tuning across a wide range of image and text generation tasks.
Comparisons with Other Models
CM3leon's performance rivals or surpasses other leading models despite being trained on a smaller dataset (3 billion text tokens compared to 40-100 billion in others). Its zero-shot performance on tasks like MS-COCO captioning and VQA2 question answering matches or exceeds that of larger models, highlighting its efficiency and effectiveness.
Applications and Potential
CM3leon's capabilities have significant implications for various applications, including:
- Image generation tools: Creating more coherent and detailed images from text prompts.
- Creative applications: Boosting creativity and enabling new forms of artistic expression.
- Metaverse applications: Enhancing user experiences and interactions in virtual environments.
Conclusion
CM3leon represents a significant advancement in generative AI, demonstrating the potential of efficient and versatile multimodal models. Its strong performance across diverse tasks, coupled with its resource efficiency, positions it as a key player in the future of AI-powered image generation and understanding.